In some of my more recent Ruby projects I've had the chance to use the Sequel gem instead of the traditional choice of ActiveRecord and have been very impressed. On one such project I needed to build a Ruby API over a legacy Oracle database with a custom sharding setup.
Database Configuration
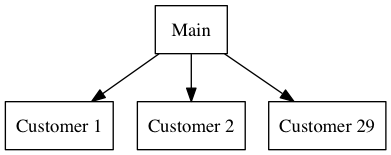
The sharding setup for this Oracle database was a central "Main" database that held basic information like user logins and global customer information. Each customer's data, however, was stored in one of dozens of customer database shards.
Some of these shards were unique to a customer in order to provide siloing of a customer's data, and some shards contained multiple smaller customers. Below is a diagram of the database setup.
Sequel vs. ActiveRecord
My initial strategy was using ActiveRecord to create a new abstract class to connect to each shard. I then wrote a class to handle creating the proper child classes which would inherit from the proper abstract class based on the customer_id and database table.
class CustomerShardManager
# ...
def self.shard_class(customer_id, table_name)
Class.new(base_by_customer_id(customer_id)) do
self.table_name = table_name
end
end
end
post = CustomerShardManager.shard_class(1, 'legacy_posts')
post.all
The post variable in the above example would return a scoped ActiveRecord class in the correct shard for a customer and table combination.
This worked to be able to run general ActiveRecord query methods, but it did not allow for setting specific data relationships or creating custom helper methods for the class.
There are some existing ActiveRecord sharding gems, like octopus, that I could have used. Octopus, however, does not allow for adding shards dynamically or pulling shard connection information from the "Main" DB instead of a static config file.
Refactoring with Sequel
On the other hand, the Sequel gem has a nice set of plugins for handling database sharding.
class Post < Sequel::Model(CUSTOMER_DB[:legacy_posts])
one_to_many :comments
def excerpt
text[0..50]
end
end
class Comment < Sequel::Model(CUSTOMER_DB[:legacy_comments])
many_to_one :post
end
class CustomerShardManager
#...
def self.use_customer(customer_id)
CUSTOMER_DB.with_server(self.shard_name(customer_id)) do
CUSTOMER_DB.synchronize { yield }
end
end
end
CustomerShardManager.use_customer(1) do
Post.all
end
This example addresses the concerns with our ActiveRecord spike and provides a simple interface to set the shard connection.
Using the with_server method that Sequel provides, we can create our own method that takes a block and within that block use the correct shard connection for all queries in that block.
We can also use the schema_caching plugin to ensure Sequel only needs to do one describe of the database tables for each shard.
Other Benefits of Sequel
- Extensive documentation with great examples of Sequel
- Multiple layers of abstraction for querying by using Datasets and Models
- [Conversion guide for ActiveRecord]((http://sequel.jeremyevans.net/rdoc/files/doc/activerecordrdoc.html)
Choosing Sequel over ActiveRecord
Based on my experience with Sequel so far I've come up with some heuristics for the types of projects on which I would consider using Sequel instead of ActiveRecord.
- Building on a legacy database
- Using a database other than the Rails standard of PostreSQL or Mysql
- Using PosgreSQL with native datatypes
- Building small web app or API outside of Rails
Would love to hear your thoughts on other types of projects that Sequel is a good fit for. See my contact info in the footer.